Introduction
When NetWorker 8 was released I said at the time it represented the biggest consolidated set of changes to NetWorker in the all the years I’d been working with it. It represented a radical overhaul and established the groundwork for further significant changes with NetWorker 8.1 and NetWorker 8.2.
![Into the Future]()
NetWorker 9 – Leaping Into the Future
NetWorker 9 is not a similarly big set of changes: it’s a bigger set of changes.
There’s a good reason why it’s NetWorker 9. This year we celebrated the 25th birthday of NetWorker, and NetWorker has done an excellent job protecting data in those 25 years, but with the changing datacentre and changing IT environment, it was time for NetWorker to change again.
![01 - NW9 Launch Screen]()
NetWorker 9 NMC Splash Screen
![Networker 9 NMC Login]()
NetWorker 9 NMC Login
The changes are more than cosmetic, of course. (Much, much more.) A while ago I posted of the need for an evolved, modern approach to data protection activities, that being the orientation of said policies and processes around service catalogues. This is something I’ve advocated for years, but it was also something I deliberately hinted at with a view towards what was coming with NetWorker 9.
The way in which we’ve configured backups in NetWorker for the last couple of decades has been much the same. When I started using NetWorker in 1996, it was by configuring groups, retention policies, schedules and clients. That’s changing.
A bright new world – Policies
NetWorker 9 represents a move towards a simpler, more containerised approach to configuration, with an emphasis on the service catalogue approach – and here’s what it looks like:
![NetWorker 9 Datazone]()
NetWorker 9 Configuration Engine
The changes in NetWorker 9 are sweeping – classic configuration components such as savegroups, scheduled staging and scheduled cloning are being replaced with a new policy engine that borrows much from the virtual machine protection engine introduced in NetWorker 8.1. This simultaneously makes it easier and faster to maintain data protection configurations, and develop more complex data protection configurations for the modern business. The policy engine is a containerised configuration system that makes it straightforward to identify and modify components of NetWorker configuration, and even have parts of the configuration dynamically adjust as required.
The core configuration process now in NetWorker 9 consists of:
- A policy, which is a container for workflows
- One or more workflows, which have:
- A set of actions and
- A list of data sources to run those actions against
If you’re upgrading NetWorker from an earlier version, your existing NetWorker configuration will be migrated for you into the new policy engine configuration. I’ll get to that in a little while. Before that though, we need to talk more about the policy engine.
Regardless of whether you’re setting up a brand new NetWorker server or upgrading an existing NetWorker server, you’ll get 5 default policies created for you:
- Server Protection
- Bronze
- Silver
- Gold
- Platinum
Each of these policies do distinctly different things. (If you’re migrating, you’ll get some additional policies. More of that in a while.)
![NW9 Protection - Policy with 2 workflows]()
NetWorker 9 Protection Window
In this case, the server protection policy consists of two workflows:
- NMC server backup – Performs a backup of the NetWorker management console database
- Server backup – Performs a bootstrap backup and a media database expiration
You can see straight away that’s two entirely different things being done within the same policy. In the world of NetWorker 8.x and lower, each Group was effectively an atomic component that did only one particular thing. With policies, you’ve got a container that encapsulates multiple logically similar activities. For instance, let’s look at the difference between the default Bronze policy and the default Silver policy:
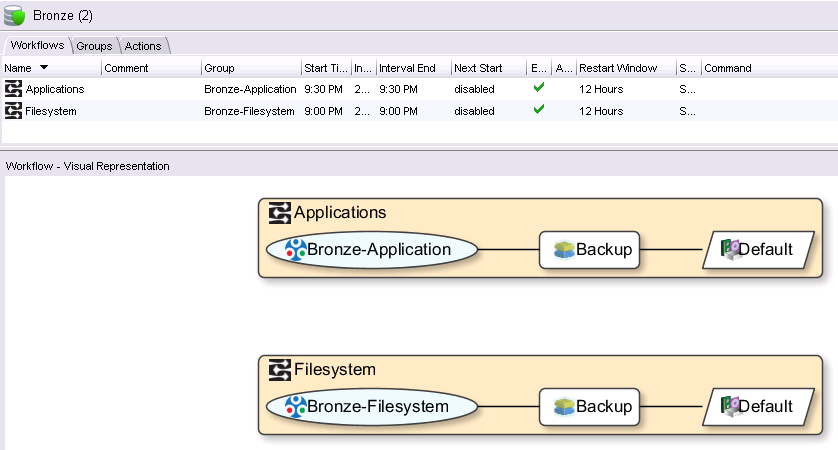
![NetWorker 9 Bronze Policy]()
NetWorker 9 Bronze Policy
The Bronze policy has two workflows – one for Applications, and one for Filesystem backups. Each workflow does a backup to the Default pool (which of course you can can change), and that’s it. By comparison, the Silver policy looks like the following:
![NetWorker 9 Silver Policy]()
NetWorker 9 Silver Policy
You can see the difference immediately – a Silver policy is about backing up, then cloning. The policy engine is geared very much towards a service catalogue design – setup a small number of policies with the required workflows and consolidate your configuration accordingly.
Oh – and here’s a cool thing about the visual policy engine – right clicking within the visualisation of the policy and changing settings, such as:
![NetWorker 9 Right Clicking in Visual Policy]()
NetWorker 9 Right Clicking in Visual Policy
The policy engine is not a like-for-like translation from older versions of NetWorker configuration (though your existing configuration is migrated). For instance, here’s an “Emerald” policy I created on my lab server:
![Sample policy with advanced cloning]()
Sample policy with advanced cloning
That policy backs up to the Daily pool and then does something new for NetWorker – clones simultaneously to two different pools – “Site-A Clone” and “Site-B Clone”. There’s also something different about the selection process for what gets backed up. The group here is…
…wait, I need to explain Groups in NetWorker 9. Don’t think they’re like the old NetWorker groups. A group in NetWorker 9 is simply a selection of data sources. That could be a collection of clients, a collection of virtual machines, a collection of NAS systems or a collection of savesets (for cloning/staging). That’s it though: groups don’t start backups, control cloning, etc.
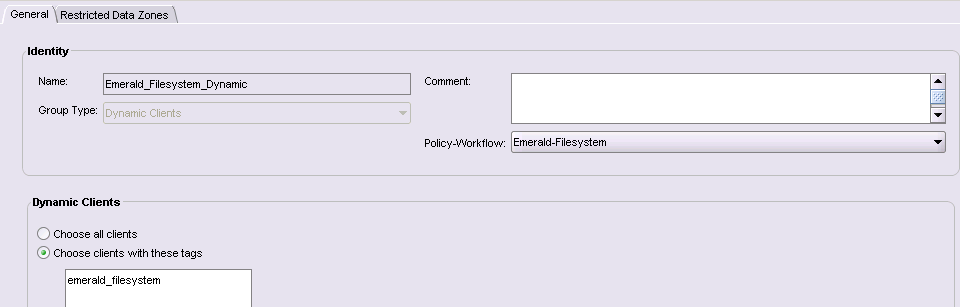
…the group here is a dynamic group. This is a new option for traditional clients. Rather than being an explicit list of clients, a dynamic group is assembled at the time the workflow is executed based on a list of tags defined in the group list. Any client with a matching tag is automatically included in the backup process. This allows for hosts to be moved easily between different policies and workflows through just by changing the tags associated with it. (Alternatively, it might be configured as automatically selecting every client.)
![NetWorker 9 Dynamic Groups]()
NetWorker 9 Dynamic Groups
There’s a lot more to the policy engine than just what I’ve covered above, but there’s also a lot more I need to cover, so I’ll stop for now and come back to the new policy engine in more detail in a future blog post.
Policy Migration
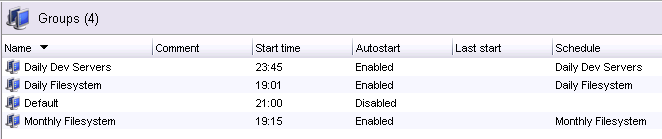
Actually, there’s one other thing I’ll mention about policies before I continue, and that’s the policy migration process. When you upgrade a NetWorker server to NetWorker 9, your existing configuration is migrated (and as you might imagine this migration process is something that’s received a lot of attention and testing). For example, a “classic” NetWorker environment that consists of a raft of groups. On migration, each group is converted into a workflow of the same name and placed under a new policy called Backup. So a basic group list of say, “Daily Dev Servers”, “Daily Filesystem” and “Monthly Filesystem” will get converted accordingly. Here’s what the group list looks like under v8 (with the default Default group):
![NetWorker 8 Group List]()
NetWorker 8 Group List
Under version 9, this becomes the following policy and workflows:
![NetWorker 9 Converted Policy]()
NetWorker 9 Converted Policy
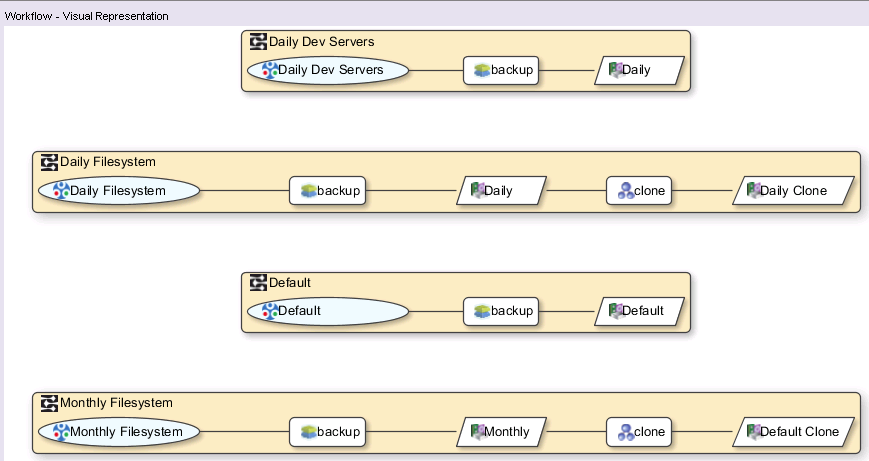
The workflow visualisation for the groups above converted into policy format is:
![NetWorker 9 Converted Policy Workflow Visualisation]()
NetWorker 9 Converted Policy Workflow Visualisation
(By the way, that “Monthly Filesystem” workflow cloning to the “Default Clone” pool was just a lazy error on my part while setting up a test server – not an error.)
I know lots of people tested some fairly hairy configuration migrations. If I recall correctly the biggest configuration I tested had over 1000 clients defined and around 300 groups, schedules, etc., associated with those clients. And I did a whole bunch of shortcuts and tricks in schedules and they converted successfully.
The back-end changes
I’ll undoubtedly do some additional blog articles about the NetWorker 9 policy engine, but it’s time to move on to other topics and other changes within NetWorker. I’ll start with some back-end changes to the environment.
Media database
The “WISS” database format has been around for as long as I can recall with NetWorker. It’s served NetWorker well, but it’s also had some limitations. As of version 9, the NetWorker media database format is now SQLite, which gives NetWorker a big boost for performance and parallelisation of media activities. As per the policy engine, this migration happens automatically for you as part of the upgrade process. (Depending on the size of your media database this may take a little while to complete, but the media database is usually fairly small for most organisations.)
NetWorker Management Console (NMC) Database
Previous versions of NetWorker have used the Sybase embedded SQLAnywhere database for NMC. NetWorker version 9 switches the NMC database to PostgreSQL. If you’re wanting to keep your existing NMC database, you’ll need to take some pre-ugprade steps to export the Sybase embedded database content into a format that can be imported into the PostgreSQL database. Be sure to read the upgrade documentation – but you were going to do that anyway, right?
License Server
Other than the options around traditional vs NetWorker capacity vs DPS capacity, NetWorker licensing has remained mostly the same for the entire 19 years I’ve been dealing with it. There was a Legato License Manager introduced some time ago but it had mainly been pushed as a means of centralising management of traditional licensing across multiple datazones. Since the capacity formats aren’t so bothered on datazone counts, LLM usage has fallen away.
With a lot of customers deploying multiple EMC products and EMC moving towards transformative enterprise licensing models, a move to a new licensing service that can handle licensing for multiple products makes sense. From a day to day basis, the licensing server won’t really change how you interact with NetWorker, but you’ll want to deal with your sales/pre-sales team or your integrator (depending on which way you procure NetWorker licenses) in order to prep for the license changes. It’s not a change to functionality of traditional vs capacity licenses, and it doesn’t signal a move away from traditional licenses either, but it is a much needed change.
Authentication System
NetWorker has by and large used OS provided user-authentication for authorisation. That might be localised on a per-system basis or it might leverage Active Directory/etc. This however left somewhat of a split between authorisation supported by NetWorker Management Console and authorisation supported from the command line. The new authentication system is effectively a single sign-on approach providing integrated authentication between NMC related activities and command line activities.
Restricted Data Zones
Restricted datazones get a few tweaks with NetWorker 9, too. I’ve had very little direct cause to use RDZs myself, so I’ll let the release notes speak for themselves on this front:
-
You can now associate an RDZ resource to an individual resource (for example, to a client, protection policy, protection group, and so on) from the resource itself. As a result, RDZ resources can no longer effect resource associations directly.
-
Non-default resources, that are previously associated to the global zone and therefore unusable by an RDZ, are now shared resources that can be used by an RDZ. Although, these resources cannot be modified by restricted administrators.
If you’re using RDZs in your environment, be sure to understand the implications of the above changes as part of the upgrade process.
Scaling
With a raft of under-the-hood changes and enhancements, NetWorker servers – already highly scaleable – become even more scaleable. If your NetWorker environment has been getting large enough that you’ve considered deploying additional datazones, now is the time to talk to your local EMC teams to see whether you still need to go down that path. (Chances are you don’t.)
NetWorker Server Platform
There are actually very few environments left where the NetWorker server itself runs on what I’d refer to as “classic” Unix systems – i.e., Solaris, HPUX or AIX. As of NetWorker 9, the NetWorker server processes (and similarly, NMC processes) will now run only on Windows 64-bit or Linux 64-bit systems. This allows a concentration of development, leveraging the substantially (I’d say massively) reduced use of these platforms for better development efficiencies. However, NetWorker client support is still extremely healthy and those platforms are also still fully supported as storage nodes.
From a migration perspective, this is actually relatively easy to handle. EMC for some time has supported cross platform migration, wherein the NetWorker media database, configuration and index (i.e., the NetWorker server) is moved from say, Linux to Windows, Solaris to Linux, Solaris to Windows, etc. If you are one of those sites still using the NetWorker server services on Solaris, HPUX or AIX, you can engage cross platform migration services and transfer across to Windows or Linux. To keep things simple (I’ve done this dozens of times myself over the years), consider even keeping the old server around, renaming it and turning it into a storage node so you don’t really have to change any device connectivity. Then, elevate the backup server to a “director only” mode where it’s not actually doing any client backup itself. All up, this sort of transition can be seamlessly achieved in a very short period of time. In short: it may be a small interruption and change to your processes, but having executed it many times myself in the past, I can honestly say it’s a very small change in the grand scheme of things, and very manageable.
In summary, the options along this front if you’re using a non-Windows/non-Linux NetWorker server are:
- Do a platform migration of your NetWorker server to Windows or Linux using your current NetWorker version, then upgrade to the new version
- Stand up a new NetWorker datazone on Windows or Linux and retain the existing one for legacy recoveries, migrating clients across
I’m actually a big fan of the former rather than the latter – I really have done enough platform migrations to know they work well and they allow you to retain everything you’ve been doing. (IMHO the only reason to not do a platform migration is if you have a very short retention period for all of your backups and you want to start with a brand new configuration approach.)
(Cross platform migrations do have to be done by an authorised party – if you’re not sure who near you can do cross platform migrations, reach out to your local EMC team and find out.)
One more thing: with the additional services now running on a NetWorker server, you could need more RAM/CPU in your server. Check out the release notes for some details on this front. Environments that have been sized with room for spare likely won’t need to worry about this at all – but if you’ve got an environment where you’ve got an older piece of hardware running as your NetWorker server, you might need to increase its performance characteristics a little.
[Clarifying point: I’m only talking about the NetWorker server platform. Traditional Unix systems remain fully supported for storage nodes and clients.]
Cloning
NetWorker gets a performance and optimisation boost with cloning. Cloning has previously been a reasonably isolated process compared to regular save or recovery operations. With NetWorker 9, cloning is now a more integrated function, leveraging the in-place recovery technology implemented in NetWorker 8.2 to speed up cloning of synthetic backups.
This has some advantages relating to parallelising clones and limiting the need for additional nsrmmd processes to handle the cloning operation, and introduces scope for exciting changes in future versions of NetWorker, too.
With continuing advances in how you can configure and manage cloning from within NetWorker policies, manual command line driven cloning is becoming less necessary, but if you do still use it you’ll notice some difference in the output. For instance:
[root@sirius ~]# mminfo -q "name=/usr,savetime>=24 hours ago" -r ssid
4278951844
[root@sirius ~]# nsrclone -b "Site-A Clone" -S 4278951844
140988:nsrclone: launching backend job on host sirius.turbamentis.int
140990:nsrclone: Backend started: job Id(160004).
85401:nsrrecopy: Input client or saveset is NULL, information not updated in jobdb
09/30/15 18:48:04.652904 Clone pool size used:4
09/30/15 18:48:04.756405 Init Clone PARAMS: Network constant(73400320) Saveset computation overhead(2000000 microsec) Threshold(600000000 microsec) MIN-Threads(16) MAX-Threads(32)
09/30/15 18:48:04.757495 Adjust Clone param: Total overhead(50541397 microsec) Threshold(12635349 microsec) MIN-threads(1) MAX-Threads(4)
09/30/15 18:48:04.757523 Add New saveset group(0x0x3fe5db0): Group overhead(50541397 microsec) Num ss(1)
129290:nsrrecopy: Successfully established direct file retrieve session for save-set ID '4278951844' with adv_file volume 'Daily.001'.
09/30/15 18:49:30.765647 nsrrecopy exiting
140991:nsrclone: Backend exited: job Id(160004).
[ORIGINAL REQUESTED SAVESETS]
4278951844;
[CLONE SUCCESS SAVESETS]
4278951844/1443603606;
Note that while the command line output is a little difference, the command line options remain the same so your scripts can continue to work without change there. However, with enhanced support for concurrent cloning operations you’ll likely be able to speed up those scripts … or replace them entirely with new policies.
Performance tuners win too
The performance tuning and optimisation guide has been getting more detailed information over more recent versions, and the one that accompanies NetWorker 9 is no exception. For example, there’s an entire new section on TCP window size and network latency considerations that a bunch of examples (and graphs) relating to the impact of latency on backup and cloning operations of varying sizes based on filesystem density. If you’re someone who likes to see what tuning and adjustment options there are in NetWorker, you’ll definitely want to peruse the new Performance Tuning/Optimisation guide, available with the rest of the reference documentation.
(On that front, NDMP has now been broken out into its own document: the NDMP User Guide. Keep an eye on it if you’re working with NAS systems.)
Additional Features
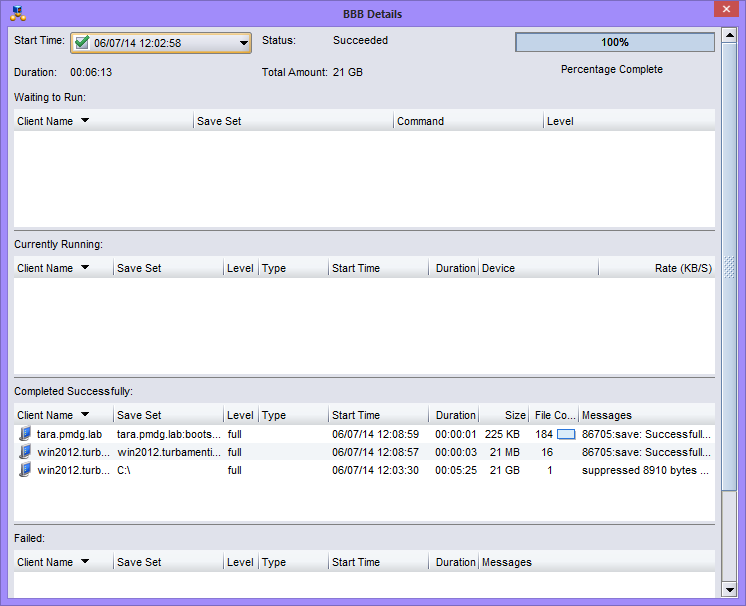
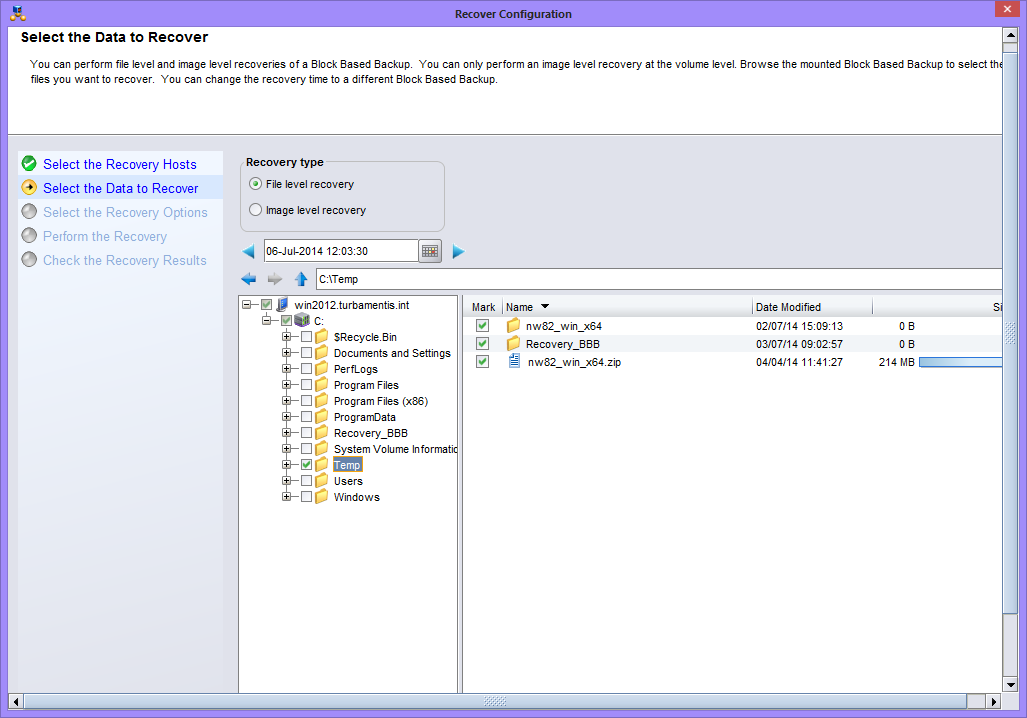
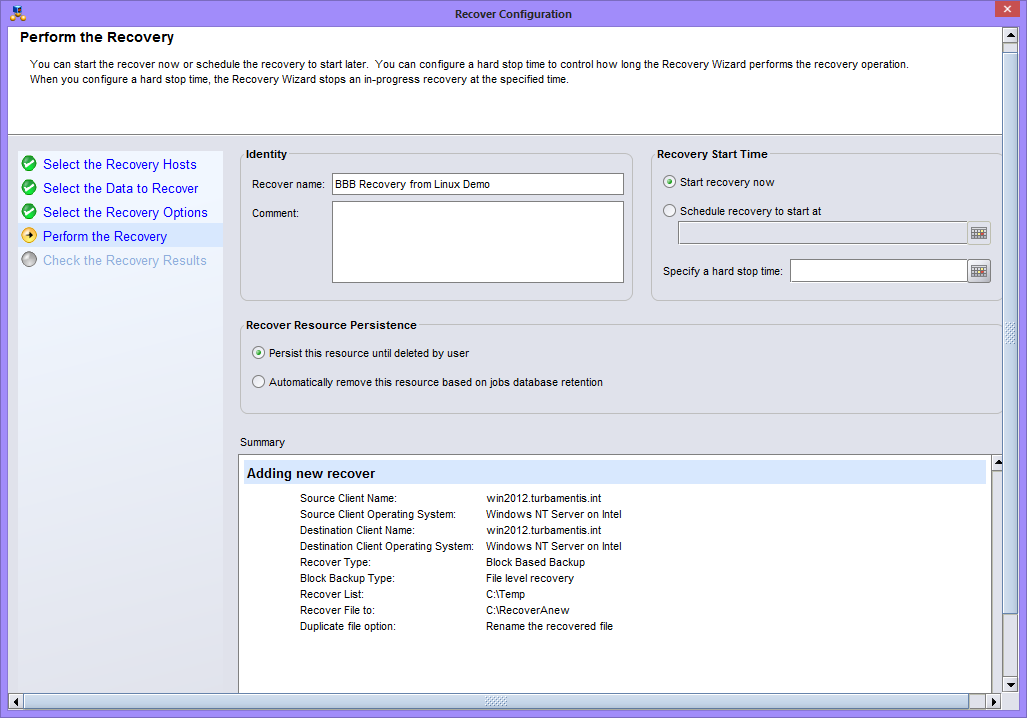
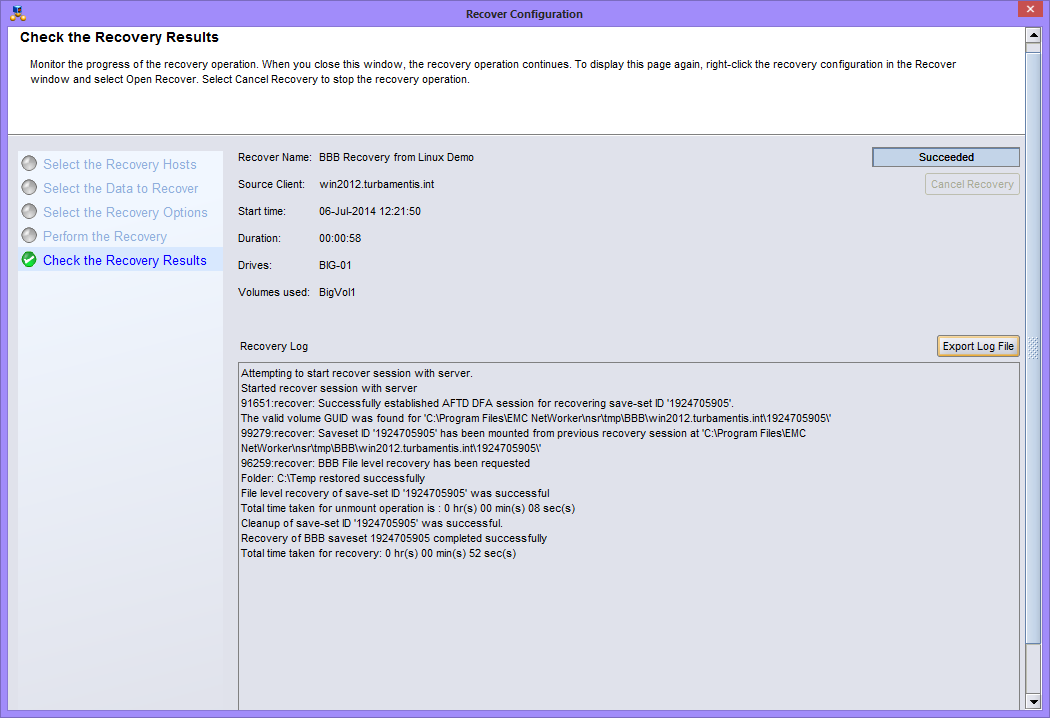
Block Based Backup (BBB) for Linux
Several Linux operating systems and filesystems now get the option of performing block based backups. This can significantly speed up the backup of large/dense filesystems – even more so than parallel save streams – by actually bypassing the filesystem entirely. It’s been available in Windows backups for a while now, but it’s hopped over the fence to Linux as well. Like the Windows variant, BBB doesn’t require image level recovery – you can do file level recovery from block based backups. If you’ve got really dense filesystems (I’m looking at large scale IMAP servers as a classic example), BBB could increase your backup performance by up to an order of magnitude.
Parallel Save Streams
Parallel Save Streams certainly aren’t forgotten about in NetWorker 9. There are now options to go beyond 4 parallel save streams per saveset for PSS enabled clients, and we’ve seen the introduction of automatic stream reclaiming, which will dynamically increase the number of active streams for a saveset already running in PSS mode to maximise the utilisation of client parallelism settings. (That’s a mouthful. The short: PSS is more intelligent and more reactive to fluctuations in used parallelism on clients.)
ProtectPoint
ProtectPoint is a pretty exciting new technology being rolled out by EMC across its storage arrays and integrates with Data Domain for the back-end storage. To understand what ProtectPoint does, consider a situation where you’ve got say, a 100TB Oracle database sitting on a VMAX3 system, and you need to back it up as fast as possible with as little an impact to the actual database server itself as possible. In conventional agent-based backups, it doesn’t matter what tricks and techniques you use to mitigate the amount of data flowing from the Oracle server to the backup environment, the Oracle server still has to read the data from the storage system. ProtectPoint is an application aware and application/integrated system that allows you to seamlessly have the storage array and the Data Domain handle pretty much the entire backup, with the data transfer going directly from the storage array to the Data Domain. Suddenly that entire-database server read load associated with a conventional backup disappears.
NetWorker v9 integrates management of ProtectPoint policies in a very similar way to how NetWorker v8.2 introduced highly advanced NAS snapshot service integration into the data protection management. This further grows NetWorker’s capabilities in orchestrating the overall data protection process in your environment.
(There’s a good overview demo of ProtectPoint over at YouTube.)
NVE
Some people want to be able to stand up and completely control a NetWorker environment themselves, and others want to be able to deploy an appliance, answer a couple of questions, and have a fully functioning backup environment ready for use. NetWorker Virtual Edition (NVE) addresses the needs and desires of the latter. For service providers or businesses deploying remote office protection solutions, NVE will be a boon – and it won’t eat into any operating system licensing costs, as the OS (Linux) is bundled with the virtual machine template file.
Base vs Extended Client Installers
For Unix systems, NetWorker now splits out the client package into two separate installers – the base version and the extended version – lgtoclnt and lgtoxtdclnt respectively. You install the base client on clients that need to get fairly standard filesystem backups. It doesn’t include binaries like mminfo, nsrwatch or nsradmin – they’re now in the extended package. This allows you to keep regular client installs streamlined – particularly useful if you’re a service provider or dealing with larger environments.
VBA
There’s been a variety of changes made to the Virtual Backup Appliance (introduced in NetWorker 8.1), but the two I want to particularly single out are the two that users have mentioned most to me over the last 18 months or so:
- Flash is no longer required for the File Level Recovery (FLR) web interface
- There’s a command line interface for FLR
If you’ve been leery about using VBA for either of the above reasons, it’s time to jump on the bandwagon and see just how useful it is. Note that in order to achieve command line FLR you’ll need to install the basic NetWorker client package on the relevant hosts – but you need to get a binary from somewhere, so that makes sense.
Module Enhancements
Both the NetWorker Module for Microsoft Applications (NMM) and NetWorker Module for Databases and Applications (NMDA) have received a bunch of updates, including (but not limited to):
- NMM:
- Simpler use of VSS.
- Block based support for HyperV and Exchange – yes, and Exchange. (This speeds up both types of backups considerably.)
- Federated backups for SharePoint, allowing non-primary databases to be leveraged for the backup process.
- I love the configuration checker – it makes getting NMM up and running with minimum effort so much easier. It’s been further enhanced in NetWorker 9 to grow its usefulness even more.
- HyperV support for Partial VSS writer – previously if you had a single VM fail to backup under HyperV the backup group running the process would register as a failure. Now the backups will continue and only the VM that fails to backup will be be declared a failure. This aligns HyperV backups much more closely to traditional filesystem or VMware style backups.
- Improved support for Federated backups of HyperV SMB 3 clusters.
- File Level Recovery GUI for HyperV virtual machine backups.
- Full integration of policy support for NMM.
- NMDA:
- Support for DDBoost over Fibre-Channel for AIX.
- Full integration of policy support for NMDA.
- Support for log-only backups for Lotus Notes systems.
- NetWorker Snapshot Manager support for features like ProtectPoint.
- Various DB2 enhancements/improvements.
- Oracle RAC discovery in the NMC configuration wizards.
- Optional use of a CONFIG_FILE parameter for RMAN scripts so you can put all the NMDA related customisations for RMAN backups into a single file (or small number of files) and keep that file/those files updated rather than having to make changes to individual RMAN scripts.
Policies, Redux
Before I wrap up: just one more thing. With the transition to a policy configuration engine, the nsrpolicy command previously introduced in NetWorker 8.1 to support Virtual Machine Protection Policies has been extensively enhanced to be able to handle all aspects of policy creation, configuration adjustment and policy/workflow execution. This does mean that if you’ve previously used nsradmin or savegrp to handle configuration/group execution processes, you’ll have to adjust some of your scripts accordingly. (It also means I’ll have to work on a new version of the Turbocharged NetWorker Administration Guide.)
Wrapping Up
I wasn’t joking at the start when I said NetWorker 9 represents the biggest set of changes I’ve ever seen in my 19 years of using NetWorker. What I will say is that these are necessary changes to prepare NetWorker for the rapidly changing datacentre. (Or even the rapidly changing datacenter if you’re so minded.)
This upgrade will require very careful review of the release notes and changed functionality, as well as potentially revisiting any automation scripts you’ve done in the past. (But you can do it.) If you’ve got a heavily scripted environment, my advice is to run up a test NetWorker 9 server and review your scripts against the changes, first evaluating whether you actually need to continue using those scripts, and then if you do, adjusting them accordingly. EMC has also prepared some video training for NetWorker 9 which I’d advise looking into (and equally I’d suggest leveraging your local EMC partner or EMC resources for the upgrade process).
It’s also an excellent time to consider revisiting your overall backup configuration and look for optimisations you can achieve based on the new policy engine and the service-catalogue approach. As I’ve been saying to my colleagues, this is the perfect opportunity to introduce policies that align to service catalogues that more precisely define and meet business requirements. If you’re not ready to do it from day zero, that’s OK – NetWorker will migrate your configuration and you’ll be able to continue to offer your existing backup and recovery services. But if you find the time to re-evaluate your configuration and reset it to a service catalogue approach, you can migrate yourself from being the “backup admin” to being the “data protection architect” within your organisation.
This is a big set of changes in NetWorker, but it’s also very much an exciting and energising set of changes, too.
As you might expect, this won’t be my only blog post on NetWorker 9 – it’s equally an energising time for me and I’m looking forward to diving into a variety of topics in more detail and providing some screen casts and videos of changes, upgrades and improvements.
(And don’t forget to wear your sunglasses: the future’s looking bright.)